This is not about C#, Java, nor any other language designed with alternative brevity.
TL;DR
Namespaces are for organising code not people
Keep namespace nesting to a minimum
Strive for memorable and easy-to-type namespaces
using namespace shouldn’t exist outside of function-bodies
Introduction
I didn’t think I had to write this post.
I thought everyone had naturally learnt, through
frustration and agony, what to avoid when using namespaces. I thought all the C-with-classes
folks had died, adapted, or ensconsed themselves in a fortress of code that
was too important for their organisation to lance.
It turns out I’m super-wrong; namespaces are getting misused all the time. I watch in
horror as someone tours me through their codebase and whispers, with pride in their eyes and idiocy on
their tongue, “here is our teams namespace”. Heavens friend, I’ll stab
you with my Learning Knife.
Namespaces For The People Code
A codebase is made up of code like algorithms, data-structures, routines,
and global variables because you’re a monster. Namespaces are a tool to organise that code
into cognitively separate chunks, so that us idiot humans can more easily store the whole
thing in our head. Good code organisation leads to an easier time navigating a codebase,
inferring where pieces may lie like a
well-drawn map.
A codebase is not made up of people, teams, JIRAs, initiatives, or whatever
bastardization of Agile Development you’ve half-remembered from a fever dream.
People aren’t present in code; a team isn’t present in code; if
you see namespaces that designate which people code belongs to you are seeing an anti-pattern.†
Don’t use namespaces to designate your company, organisation, or team. Use namespaces to
separate libraries, systems, and code into cognitively distinct areas within your codebase.
⁂
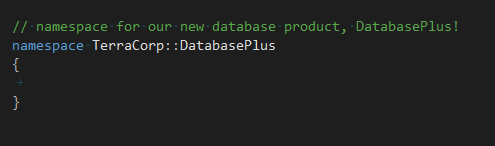
I shall now rant about top-level company namespaces.
An all-encompassing namespace that bears the name of an organization is the most common
mistake I see with “people namespaces”. If this top-level namespace is
the only one of its kind then I suspect narcissism as much as a lack of understanding, and
you should delete it.
A top-level company namespace only does one functional thing - it prevents any nested namespace
from clashing with an external library. In all my years I can not recall any
top-level namespace clashing with another, and it is straightforward to work around clashing
namespaces.
The downside is that it’s a
pain to type every time. How do engineers get around that? They put everything inside the
organisation namespace, so it’s like it doesn’t exist in the first place. Wow what smart
people, they effectively deleted your namespace for you. Save them the trouble and don’t
include it from the start.
“But what about all those little utility functions and things, they can’t just live in the global
namespace like a tramp in the woods”. Firstly, weird analogy dude. Secondly, this pattern of
thinking is wrong. You should see a collection of useful functions and think “I should wrap these
in a library with a nice short name”, like std except not that because it’s already taken.
⁂
† I realise that there may be teams that share the same name as the piece of technology
they’re working on - for which there might be a corresponding namespace. I hope you’re smart enough to
realise that I’m not talking about you. If the namespace makes sense for the code, I don’t
care if your team is similarly named. Call your team Global Namespace for all I care.
I’m offended you made me write this caveat out.
Go Wide, Not Deep
In life if you wish to promote a particular behaviour I recommend removing barriers that
makes that difficult. The two primary barriers to engineers
engaging with your namespaces are keystrokes-per-second, and thinking-units-per-interaction.
Deeply nested namespaces fall afoul of both these.
Engineers will hate a codebase if they have to type a lot of characters to access every
function or type within it. They will stop being good citizens and go rogue, they will
start writing using namespace, and they will call you names. You will
have failed with your design because it is hard to use.
Remembering where particular functionality lies becomes harder in a codebase with
deeply-nested namespaces. I speculate due to
the lossy nature of human memory that this falloff is super-linear. In every case
it is worse. If you have usable functionality in a three-levels-deep namespace,
you are probably in a sad place.†
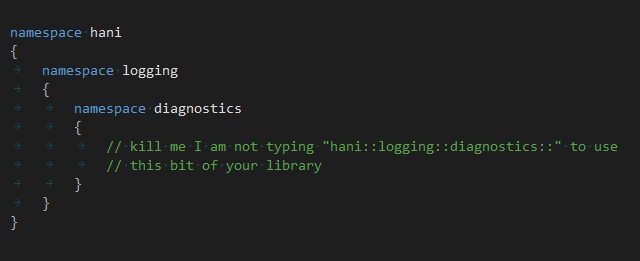
The solution, friends, is to nest less.
If your codebase is large with nicely named distinct bits there is the temptation to carroul these
pieces into groups; engineers are frightened of numbers greater than six.
Muster your courage and allow fifteen, twenty adjacent namespaces.
Realise that the number of namespaces has not changed. Instead the amount of overhead to engage with
them is reduced. Engineers do not have to remember to which namespaces the namespaces belong.
⁂
† Yeah I’m not including internal or detail namespaces. Those are an artefact of
the language, and not the topic today.
A Rose By Any Other Namespace
(This bit is more subjective than the obviously factual sections above)
Names are hard. I get that. That’s why salespeople are employed to think up
the perfect intersection between a word that is catchy and a word that represents a product.
You have to be that salesperson for your own code. Codebases quickly grow too large for people to know the contents
of every line. In a large enough codebase you must sell the functionality of the code within. We
must sell to ourselves, because future us don’t remember. The engineer I curse with the most frequency
is me of coding-past.
The name of a product is outside the scope of this rant essay. I don’t have rules for what
constitutes a good name for a product. I do have rules for what makes up a good namespace. You
may notice the concepts of keystrokes-per-second, and thinking-units-per-interaction rear
their heads again. At the end of this list you will know why I consider std to be a good namespace.
Lean towards catchy rather than descriptive. People really
can’t understand a library from just its name. Even if testface implies a testing
library, one can not infer much else. Give up the battle and use a name people remember.
This is very true for products, but it is also true for any area of your codebase.
Err on the side of brevity. We move our mouths much faster than we type - let people say
the name of your product, but type a shorthand when writing code. Shorter things are easier to remember too,
especially if you’re sipping that Web 2.0 juice and naming your things kodi or something
nonsensicle.
Fingers don’t handle consecutive repositioning well. Avoid words for which a sequence of
letters requires consecutively repositioning the same finger. Compare the ease of typing ede:: with
eye::, or juhu:: with jihi::, and bask in this trivial revelation.
Double letters like jeep:: or folly:: are fine but avoid double letters on little fingers
(like zz or pp). Those fingers are weak and will slow you down.
Never end a namespace with a letter that requires the little-finger on the left hand. I
realise keyboards are not identical everywhere, but take a punt that 95% of people will
QWERTY until they die. After a namespace in C++ you type a colon :, and
if you are typing correctly you use the little-finger on your left hand to press Shift.
Using Namespace
You should never place a using namespace statement in any scope greater than a
function-body. It’s well-known that placing said statement in a header-file is
obviously bad, as you pollute all translation units which include that header-file. Given
engineers propensity to include random header files at the drop of a hat and you will soon
have polluted your whole codebase. These days, with the proliferation of unity builds,
the translation-unit scope is no longer safe. That means you can’t put a using namespace at
the top of your .cpp file as a unity build will pollute all adjacent source files. So… don’t do that.
A quick syntax-based overview of C++20 Concepts, as they are in the standard (circa January 2020).
TL;DR
With the release of MSVC 16.3 (and some holiday time), I decided to convert my Eric Niebler-inspired templated SFINAE
hocus-pocus approximation of concepts into actual concepts. But it’s so hard to find up-to-date docs on how the
syntax is actually supposed to be. After some experiements (and reading), here are examples to get you started.
Using Concepts in Functions
Let’s come up with a synthetic problem that SFINAE/Concepts can fix. So, we have a log function for numbers, I guess.
We want to treat integers and floating-point numbers differently I suppose? So let’s have one function, log, that forwards
the handling to different places.
Example
This doesn’t compile, but this is basically what we want:
// pick between these two somehowtemplate<typenameT>voidlog(T&&x){log_integral(x);}template<typenameT>voidlog(T&&x){log_floating_point(x);}
SFINAE
This is what you’d write today, or maybe I should say yesterday? Haha nah your workplace won’t catch up for years.
This won’t make sense until the very next example, but you can also place the requires clause
after the parameter-list. This allows you to do some funky things with decltype, shown here.
You need to std::remove_reference_t your decltypes for many concepts (some you don’t)
I don’t recommend doing this unless you really have to, it’s hard to read
C++20 allows you to write generic functions which take auto as the parameter type, just like generic lambdas.
You then can omit the template specification. You don’t get a typename, so you have to decltype the argument.
Now the above makes more sense!
Here’s a slightly more complex example showing things together:
template<typenameD,std::integralT>requiresstd::assignable_from<D,T>voidassign_the_thing(D&dest,T&&x){dest=std::forward<T>(x);}// here's the generic-function version.//// in this case we don't need to std::remove_reference_t our decltypes because// we actually want to know if we can assign the lvalue/rvalue x to the lvalue dest//// it's up to you which you prefervoidassign_the_thing(auto&dest,std::integralauto&&x)requiresstd::assignable_from<decltype(dest),decltype(x)>{dest=std::forward<decltype(x)>(x);}
Writing A Concept
Okay so you can use concepts defined in the standard library. Now let’s write a concept, because
that’s where the real magic is. And everyone loves magic.
The simplest concept
Concepts are defined by a compile-time boolean expression. So this restricts nothing:
template<typenameT>conceptsuperfluous=true;
A concept specified using a boolean
Here we create a concept from a standard-library compile-time boolean. This is, in fact, how
std::integral is (probably) implemented.
// note -- std::integral & std::floating_point are conceptstemplate<typenameT>conceptnumber=std::integral<T>||std::floating_point<T>;
You want certain expressions to be valid
We can require the type to be able to do things. To do so we wrap expressions in braces:
template<typenameT>conceptyou_can_increment_it=requires(Tx){{++x};};// look, this concept requires two typestemplate<typenameX,typenameY>conceptthey_are_mathsy=requires(Xx,Yy){{x*y};{x/y};{x+y};{x-y};};
You care about the types returned
Using some serious voodoo magic, C++20 will substitute the evaluated result-type
of the expression into the return-type-requirement, at the front, which is a little
weird, but okay.
template<typenameT>conceptyou_can_increment_it=requires(Tx){// incrementing doesn't change type//// the substitution is evaluated as:// std::same_as<your-expressions-resultant-type, T>{++x}->std::same_as<T>;// addition results in something convertible to an int{x+x}->std::convertible_to<int>;};
You want to inspect types, members, and methods
Prefacing a statement in the requires clause with typename tells the compiler
you’re about to interrogate the type to ensure it has a sub-type. If it doesn’t,
the concept hasn’t been satisfied.
template<typenameT>conceptits_a_dragon=requires(Tx){// this type trait must be able to be instantiatedtypenamedragon_traits<T>;// T has a nested typename for some pointer idk use your imaginationtypenameT::dragon_clan_ptr;{x.breathe_fire()};{x.dragon_breath_firepower()}->std::convertible_to<uint>;};// notice we don't need a 'x' argument if we don't do any expression stufftemplate<typenameT>conceptits_a_knight=requires{typenameT::castle_type;typenameT::armour_type;typenameknight_traits<T>;};
Invovled Example
Here we use several of our previous ideas to describe something we can new & delete.
template<typenameT>conceptdynamically_allocatable=std::default_constructible<T>&&std::copy_constructible<T>&&std::destructible<T>requires(Ta,size_tn){requiresstd::same_as<T*,decltype(newT)>;requiresstd::same_as<T*,decltype(newT(a))>;requiresstd::same_as<T*,decltype(newT[n])>;{a.~T()}noexcept;// destructor must be noexcept (and exist!){deletenewT};{deletenewT[n]};};
Constrained auto, but everywhere
“Constrained auto” means you jam a concept in front of auto to ensure whatever type
it is conforms to the concept. You can put this damn near anywhere you use auto.
Sometimes you have things (often allocators) that have no members and you want them not to be given arbitrary size.
Let’s say, for the sake of argument, you’re writing a drop-in replacement of std::vector. You’ll quickly notice that if you’re to maintain a standards-compatible interface, you’ll need to provide support for custom allocators. More importantly, you’ll need to support the storage of instances of allocators, because these days allocators can be stateful. It’s more than likely you’ve never used a custom allocator, because no one does. Well, great news! Someone out there does. I guess that means you’re storing an instance of Allocator (your templated type) in your vector class. But wait!
The Problem
Allocators don’t necessarily have any members. Actually they probably don’t. The default allocator almost certainly; the default allocator is defined to be stateless. It (probably) simply hands off to system malloc/free calls, and lets the operating system handle the free-list, fragmentation, etc. It does not contain any members. What is the size of such a type? It has no members, so surely zero? Of course not. The reasoning makes sense when you consider the following:
// empty typestructdragon_t{};dragon_thenry,oliver;// surely the addresses are different, but if the size of// dragon_t was zero, they would probably overlap?dragon_t*p1=&henry;dragon_t*p2=&oliver;
C++ guarantees two differing instances have differing addresses. This means that if the address must differ, and a byte is the smallest addressable unit in C++ (it is), then a struct is going to take up at least one byte. henry and oliver would “stack” on top of each other otherwise. It’s very likely that by storing an instance of Allocator we’ll be storing an extra one byte, at least, in our vector reimplementation. That’s a byte that contributes absolutely nothing. Fortunately there’s a way around this. It’s not even terrible.
Empty Base Optimization
Maybe you’ve guessed at where this is going by the name of the post. I’ve told you what Empty would be, and we all love optimizations. All that leaves is base, and yeah, I’m talking about a base class. Above I wrote that “the address of two differing instances also differs”. Since dragon_t has no size, the compiler gives it some size. But what if we have other stuff that we care about? And then what if we inherit from dragon_t?
structdragon_t{};structwise_dragon_t:dragon_t{uint32_tintelligence;};wise_dragon_tmatthew;wise_dragon_tcatherine;static_assert(sizeof(matthew)==sizeof(uint32_t),"as expected");ASSERT(&matthew!=&catherine&&sizeof(matthew)==sizeof(catherine),"different but equal");
Bam. When our base-class is empty, it contributes nothing to our size. This is because the address of matthew and catherine still differ. Since dragon_t has no size, if we static_cast from wise_dragon_t to dragon_t, we’ll probably get the same pointer. But that’s cool and totally allowed, and even expected. Let’s note that if wise_dragon_t was also empty, it would be given a byte of size.
It’s this interaction that leads us to Empty Base Optimization. We are going to inherit from our allocators. It does not make sense to do this when our allocators have members - all it does is pollute our types with the members and methods of the base-type, for no gain.
Putting It Into Practice
So we want to integrate Empty Base Optimization into our std::vector replacement.
There are two approaches to this:
We could inherit from a templated base class (base_vector) that either uses EBO or not with our allocator
One of our members could be a compressed pair:
A compressed pair (à la boost::compressed_pair) takes two types, and activates EBO selectively. A vector usually has three members: pointer, size, and capacity (sometimes this information is encoded as three pointers). This pointer is an excellent candidate for combining with our allocator. The pointer and the allocator are already tightly associated — after all, the allocator initialized the pointer. This also removes complexity from the definition and visualization of our vector, which brings its own benefits.
Let’s look at a sample implementation:
template<typenameT,typenameAlloc=std::allocator<T>>structvector{// implementation...private:size_tcapacity_,size_;// this member contains the pointer and the allocator, possibly EBOdour_ebo_structure_t<T,Alloc>data_;};
Let’s first ask ourselves if it’s worth adapting a more generalized type (compressed_pair) for this job. our_ebo_structure_t is essentially a trussied-up compressed-pair; is there any benefit in writing a more specialized version? I am arguing yes, for two reasons: Firstly, we will be writing functions that perform intricate pointer-and-allocator operations, and it would be kind of weird if they were written against a general
compressed_pair. Secondly this structure is emulating a pointer, with an allocator along for the ride. We can provide pointer-specific operators like
operator [], operator +, etc., to provide a psuedo-pointer interface.
We are using EBO when our allocator has no members, or is empty, in std nomenclature. We will define a base class that either stores the allocator as a member, or inherits from it:
We are going to write a version for when std::is_empty is true, and when it is false. We will allow our derived types to access the allocator through the method allocator(), which is implemented differently in either case. I have omitted the constructors (and const versions of the methods) for brevity:
template<typenameAlloc>structbase_memory_t<Alloc,false>{autoallocator()->Alloc&{returnallocator_;}private:Allocallocator_;};// this is one of the only times I've ever used protected inheritancetemplate<typenameAlloc>structbase_memory_t<Alloc,true>:protectedAlloc{autoallocator()->Alloc&{returnstatic_cast<Alloc&>(*this);}};
Implementation II: Interface
Inheriting from this base type will be our memory_t type, which is going to be typed upon T, the type of the memory, and Allocator, which is what all the fuss is about. I want people to be able to express “this is memory full of [sic] integers, handled by this allocator”. If you don’t want to type your memory, you could leave it out, or simply pass along std::byte.
I have now demonstrated the benefits of EBO and how to jam it into your code. I’m going to stop here, and show you an incomplete reference of the type, to demonstrate some of the features that would be lacking from using a more generalized compressed pair. I hope if you’re ever writing something that requires allocators you get a pay raise, but also since you clearly care about allocations, you write your code to minimize space in the common path.
So I burnt out a bit towards the end of last year, just as I started this blog - perhaps because I did. Either way, it went dead. And that isn’t cool. But now I’m back, ready to continue working on shiny, voxelizing things. This post is going to basically be a bit of an algorithm/code dump. But that’s cool, because it’s hard to find this stuff explained online.
Triangle-AABB Intersections
Finding a modern algorithm for AABB-triangle intersection wasn’t terribly difficult. All the major papers I have previously mentioned (in my only other blog post to date) reference the same one: Fast Parallel Surface and Solid Voxelization on GPUs - Schwarz-Seidel 2010. As their paper mentions, this algorithm expands into fewer instructions than the standard Seperating Axis Theorem-based algorithm, by Akenine-Möller. The SAT-based algorithm is the easiest thing to find on the web when you search for triangle-box intersection. It’s also crazy-full of macros. I can’t imagine anyone uses it without modifying it first.
For now, I’ve decided to first generate Sparse Voxel Octrees “offline”. For you kids not in the know, that means before the application runs - a build step. After I get that all working, I’ll try and GPU-accelerate it. Eventually, ideally, the voxelization pipeline will be flexible enough to voxelize large data-sets offline, and smaller objects in real-time, a la Crassin et al. But first we need to correctly intersect boxes and triangles.
The Algorithm, An Explanation
This algorithm is nice because it allows for a bunch of per-triangle setup to be done, and then minimal intructions performed per-voxel.
So, referencing our paper, I’ll outline how it works very quickly:
Take the box, and the bounding-box of the triangle, and check if they overlap. If they don’t, no intersection.
Take the plane the triangle lies upon and test to see if it intersects the box. If it doesn’t, no intersection.
For each axis-plane (xy, yz, zx), project the box and the triangle onto the plane, and see if they overlap. If any don’t, no intersection.
Step 1 is incredibly obvious and is performed in every algorithm I ever saw. Step 2 requires calculating something called the critical point, in relation to the triangle-normal. If you imagine a light being shone from very far away, in the direction of the triangle-normal, then the critical-point would be the first (closest) point hit by the incoming light. Honestly it was easy to blindly implement Step 2 so I didn’t really pay much attention. Step 3 was far more difficult, because of how Schwarz & Seidel decided to write their paper. Rather than continue describing the algorithm in abstract, they instead describe the rest of the per-axis-plane algorithm in terms of the xy-plane. Which would be fine, save for that they don’t mention which other two planes should also be implemented. So silly old me implemented the xy-plane, the xz-plane, and the yz-plane. Spot the error? Yeah, it should be the zx-plane, not the xz-plane. I still don’t know why that’s important, but it’s the difference between happiness and sadness.
The Algorithm, Implementation
Here I’ve just code-dumped the algorithm in C++. I think it’s readable enough. Keep in mind I use homogenous coordinates (points have 1.f in the w-component, vectors have 0.f). I haven’t yet figured out how to format it nicely so it scrolls horizontally yet.
//// some things to note:// - point4f is a function that returns a vector4f with the w-component set to 1.f//inlineautointersect_aabb_triangle(aabb_tconst&box,triangle_tconst&tri)->bool{// bounding-box testif(!intersect_aabbs(box,tri.aabb()))returnfalse;// triangle-normalauton=tri.normal();// p & delta-pautop=box.min_point();autodp=box.max_point()-p;// test for triangle-plane/box overlapautoc=point4f(n.x>0.f?dp.x:0.f,n.y>0.f?dp.y:0.f,n.z>0.f?dp.z:0.f);autod1=dot_product(n,c-tri.v0);autod2=dot_product(n,dp-c-tri.v0);if((dot_product(n,p)+d1)*(dot_product(n,p)+d2)>0.f)returnfalse;// xy-plane projection-overlapautoxym=(n.z<0.f?-1.f:1.f);autone0xy=vector4f{-tri.edge0().y,tri.edge0().x,0.f,0.f}*xym;autone1xy=vector4f{-tri.edge1().y,tri.edge1().x,0.f,0.f}*xym;autone2xy=vector4f{-tri.edge2().y,tri.edge2().x,0.f,0.f}*xym;autov0xy=math::vector4f{tri.v0.x,tri.v0.y,0.f,0.f};autov1xy=math::vector4f{tri.v1.x,tri.v1.y,0.f,0.f};autov2xy=math::vector4f{tri.v2.x,tri.v2.y,0.f,0.f};floatde0xy=-dot_product(ne0xy,v0xy)+std::max(0.f,dp.x*ne0xy.x)+std::max(0.f,dp.y*ne0xy.y);floatde1xy=-dot_product(ne1xy,v1xy)+std::max(0.f,dp.x*ne1xy.x)+std::max(0.f,dp.y*ne1xy.y);floatde2xy=-dot_product(ne2xy,v2xy)+std::max(0.f,dp.x*ne2xy.x)+std::max(0.f,dp.y*ne2xy.y);autopxy=vector4f(p.x,p.y,0.f,0.f);if((dot_product(ne0xy,pxy)+de0xy)<0.f||(dot_product(ne1xy,pxy)+de1xy)<0.f||(dot_product(ne2xy,pxy)+de2xy)<0.f)returnfalse;// yz-plane projection overlapautoyzm=(n.x<0.f?-1.f:1.f);autone0yz=vector4f{-tri.edge0().z,tri.edge0().y,0.f,0.f}*yzm;autone1yz=vector4f{-tri.edge1().z,tri.edge1().y,0.f,0.f}*yzm;autone2yz=vector4f{-tri.edge2().z,tri.edge2().y,0.f,0.f}*yzm;autov0yz=math::vector4f{tri.v0.y,tri.v0.z,0.f,0.f};autov1yz=math::vector4f{tri.v1.y,tri.v1.z,0.f,0.f};autov2yz=math::vector4f{tri.v2.y,tri.v2.z,0.f,0.f};floatde0yz=-dot_product(ne0yz,v0yz)+std::max(0.f,dp.y*ne0yz.x)+std::max(0.f,dp.z*ne0yz.y);floatde1yz=-dot_product(ne1yz,v1yz)+std::max(0.f,dp.y*ne1yz.x)+std::max(0.f,dp.z*ne1yz.y);floatde2yz=-dot_product(ne2yz,v2yz)+std::max(0.f,dp.y*ne2yz.x)+std::max(0.f,dp.z*ne2yz.y);autopyz=vector4f(p.y,p.z,0.f,0.f);if((dot_product(ne0yz,pyz)+de0yz)<0.f||(dot_product(ne1yz,pyz)+de1yz)<0.f||(dot_product(ne2yz,pyz)+de2yz)<0.f)returnfalse;// zx-plane projection overlapautozxm=(n.y<0.f?-1.f:1.f);autone0zx=vector4f{-tri.edge0().x,tri.edge0().z,0.f,0.f}*zxm;autone1zx=vector4f{-tri.edge1().x,tri.edge1().z,0.f,0.f}*zxm;autone2zx=vector4f{-tri.edge2().x,tri.edge2().z,0.f,0.f}*zxm;autov0zx=math::vector4f{tri.v0.z,tri.v0.x,0.f,0.f};autov1zx=math::vector4f{tri.v1.z,tri.v1.x,0.f,0.f};autov2zx=math::vector4f{tri.v2.z,tri.v2.x,0.f,0.f};floatde0zx=-dot_product(ne0zx,v0zx)+std::max(0.f,dp.y*ne0zx.x)+std::max(0.f,dp.z*ne0zx.y);floatde1zx=-dot_product(ne1zx,v1zx)+std::max(0.f,dp.y*ne1zx.x)+std::max(0.f,dp.z*ne1zx.y);floatde2zx=-dot_product(ne2zx,v2zx)+std::max(0.f,dp.y*ne2zx.x)+std::max(0.f,dp.z*ne2zx.y);autopzx=vector4f(p.z,p.x,0.f,0.f);if((dot_product(ne0zx,pzx)+de0zx)<0.f||(dot_product(ne1zx,pzx)+de1zx)<0.f||(dot_product(ne2zx,pzx)+de2zx)<0.f)returnfalse;returntrue;}
This is the first post of my blog. There are many like it, but this one is mine.
Overview
This blog is mainly going to be documenting my journey in writing a voxel-based graphics engine (called shiny). This isn’t my first trip to the rodeo, but it is the first time I’ve done anything with voxels. My first goal is to replicate Cyril Crassin et al.’s thesis Gigavoxels, in DirectX 11. I currently have a Sparse Voxel Octree… viewer thing. It correctly displays a non-mip-mapped 3D texture (the bricks) by navigating an octree, stored in a buffer, in the fragment shader. Using Shader Model 5, of course. So, that’s nice. Next will be writing a voxelization tool to voxelize polygonal models, and then completing the Gigavoxels implementation. After that… who knows.
I will probably also write about C++ stuff in general. Like how sweet lambdas are.
Voxelization
There are several recent publications regarding voxelization, most notably Baert, Lagae, and Dutrè’s Out-of-Core Construction of Sparse Voxel Octrees, Crassin and Green’s Sparse Voxelization, and Rauwendaal and Bailey’s Hybrid Computational Voxeization Using the Graphics Pipeline. I’m currently just trying to wrap my head around how easy it will be to merge their approaches to get an out-of-core voxelisation tool that utilizes the graphics pipeline for serious throughput. My gut feeling is: totally doable.
Gigavoxels
The step afterwards requires writing the interface for the atomic buffer operations, after which I can begin to implement the remainder of Gigavoxels. I don’t even understand the buffer read/write mechanism described in the thesis, about loading data asychronously on-demand. But that’s a while away. I intend to document the architecture of the engine in this blog. I’ll also probably write out my (re-)discoveries about voxels along the way, mainly to solidify my understanding.